@Gear_Shift wrote:
Title. After installing Rockstor for the first time, I get a blank webui after setting up the initial user.

Posts: 1
Participants: 1
@Gear_Shift wrote:
Title. After installing Rockstor for the first time, I get a blank webui after setting up the initial user.
Posts: 1
Participants: 1
@mclark wrote:
Following the instructions for installing a virtual rockstor on KVM,
http://rockstor.com/docs/kvm_setup.html
There is a note about networking, “In the following guide the default KVM networking arrangement is used (NAT)” As noted this does not permit one to access your rockstor from your LAN. If I change the KVM network for the virtual machine to a bridge I can access the rockstor web portal from PC’s on the LAN, but not from the virtual host. You are warned about this in the Virtual Machine Manager when selecting the bridge network interface for the VM.
Is there a way to set up the KVM network so you can access the rockstor web interface from both the virtual host and other PC’s on the LAN?
I used the NAT network and a route command on a Mint install but still could not access the web gui on 192.168.122.117 (the default address with the KVM on NAT).
Posts: 1
Participants: 1
@iecs wrote:
when removing a disk from a pool
[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
the version of rockstor 3.9.1-16
Detailed step by step instructions to reproduce the problem
[write here]
Web-UI screenshot
Error Traceback provided on the Web-UI
[paste here]but it is strange that when I am trying to remove another disk
it says a removing is in process
Error running a command. cmd = /sbin/btrfs device delete /dev/disk/by-id/ata-ST5000LM000-2AN170_WCJ1CPJH /mnt2/st5000danpan. rc = 1. stdout = [’’]. stderr = [“ERROR: error removing device ‘/dev/disk/by-id/ata-ST5000LM000-2AN170_WCJ1CPJH’: add/delete/balance/replace/resize operation in progress”, ‘’]
Traceback (most recent call last):File “/opt/rockstor/src/rockstor/rest_framework_custom/generic_view.py”, line 41, in _handle_exception
yield
File “/opt/rockstor/src/rockstor/storageadmin/views/pool.py”, line 470, in put
resize_pool(pool, dnames, add=False)
File “/opt/rockstor/src/rockstor/fs/btrfs.py”, line 210, in resize_pool
return run_command(resize_cmd)
File “/opt/rockstor/src/rockstor/system/osi.py”, line 121, in run_command
raise CommandException(cmd, out, err, rc)
CommandException: Error running a command. cmd = /sbin/btrfs device delete /dev/disk/by-id/ata-ST5000LM000-2AN170_WCJ1CPJH /mnt2/st5000danpan. rc = 1. stdout = [’’]. stderr = [“ERROR: error removing device ‘/dev/disk/by-id/ata-ST5000LM000-2AN170_WCJ1CPJH’: add/delete/balance/replace/resize operation in progress”, ‘’]the other disk I ordered to be removed before is ata-ST5000LM000-2AN170_WCJ1F9RB
Posts: 1
Participants: 1
@Bee_rii wrote:
I’ve got a little gigabyte minipc with a J1900 celeron processor and 4 gb of ram. I’ve got a 4gb disk in a 6GBps caddy. There’s also an internal drive. The 4gb drive I let rockstor format it to btrfs and the internal drive I let it format as the install disk.
I think I should be getting faster transfer rates over samba and just want to know if there is anything I can do to optimise. Right now I’m only getting about 11MBps.
I’ve included a few outputs below. If you need any other outputs let me know.
The output of my write test to the external drive is
dd if=/dev/zero of=/mnt2/Media/test1.img bs=1MB count=10000 10000+0 records in 10000+0 records out 10000000000 bytes (10 GB) copied, 63.0068 s, 159 MB/sLSPCU
Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 4 On-line CPU(s) list: 0-3 Thread(s) per core: 1 Core(s) per socket: 4 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 55 Model name: Intel(R) Celeron(R) CPU J1900 @ 1.99GHz Stepping: 8 CPU MHz: 1678.039 CPU max MHz: 2415.7000 CPU min MHz: 1332.8000 BogoMIPS: 3998.40 Virtualization: VT-x L1d cache: 24K L1i cache: 32K L2 cache: 1024K NUMA node0 CPU(s): 0-3 Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology tsc_reliable nonstop_tsc aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 cx16 xtpr pdcm sse4_1 sse4_2 movbe popcnt tsc_deadline_timer rdrand lahf_lm 3dnowprefetch epb tpr_shadow vnmi flexpriority ept vpid tsc_adjust smep erms dtherm ida aratLSPCI
00:00.0 Host bridge: Intel Corporation Atom Processor Z36xxx/Z37xxx Series SoC Transaction Register (rev 0e) 00:02.0 VGA compatible controller: Intel Corporation Atom Processor Z36xxx/Z37xxx Series Graphics & Display (rev 0e) 00:13.0 SATA controller: Intel Corporation Atom Processor E3800 Series SATA AHCI Controller (rev 0e) 00:14.0 USB controller: Intel Corporation Atom Processor Z36xxx/Z37xxx, Celeron N2000 Series USB xHCI (rev 0e) 00:1a.0 Encryption controller: Intel Corporation Atom Processor Z36xxx/Z37xxx Series Trusted Execution Engine (rev 0e) 00:1b.0 Audio device: Intel Corporation Atom Processor Z36xxx/Z37xxx Series High Definition Audio Controller (rev 0e) 00:1c.0 PCI bridge: Intel Corporation Atom Processor E3800 Series PCI Express Root Port 1 (rev 0e) 00:1c.1 PCI bridge: Intel Corporation Atom Processor E3800 Series PCI Express Root Port 2 (rev 0e) 00:1c.2 PCI bridge: Intel Corporation Atom Processor E3800 Series PCI Express Root Port 3 (rev 0e) 00:1c.3 PCI bridge: Intel Corporation Atom Processor E3800 Series PCI Express Root Port 4 (rev 0e) 00:1f.0 ISA bridge: Intel Corporation Atom Processor Z36xxx/Z37xxx Series Power Control Unit (rev 0e) 00:1f.3 SMBus: Intel Corporation Atom Processor E3800 Series SMBus Controller (rev 0e) 02:00.0 Network controller: Realtek Semiconductor Co., Ltd. RTL8723BE PCIe Wireless Network Adapter 03:00.0 Ethernet controller: Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller (rev 0c)LSUSB
Bus 002 Device 002: ID 152d:0578 JMicron Technology Corp. / JMicron USA Technology Corp. JMS567 SATA 6Gb/s bridge Bus 002 Device 001: ID 1d6b:0003 Linux Foundation 3.0 root hub Bus 001 Device 002: ID 13d3:3410 IMC Networks Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hubhdparm
Timing cached reads: 3158 MB in 2.00 seconds = 1579.75 MB/sec Timing buffered disk reads: 528 MB in 3.00 seconds = 175.76 MB/secbtrfs fi show
Label: 'rockstor_rockstor' uuid: 0aa80e9c-887c-41f1-831c-a061c1f156b8 Total devices 1 FS bytes used 2.30GiB devid 1 size 219.21GiB used 21.02GiB path /dev/sda3 Label: 'MainShare' uuid: 4a3311ec-e8cd-44aa-bde3-09bbd83f87cf Total devices 1 FS bytes used 44.63GiB devid 1 size 3.64TiB used 47.02GiB path /dev/sdb
Posts: 3
Participants: 2
@phillxnet wrote:
As per more recent changes to our Update Channels docs and following our ongoing developer doc:
We now have very early testing channel rpms available for openSUSE Leap15.1 and Tumbleweed. The latter is particularly experimental and is used by developers as a ‘heads up’ on what’s coming. Neither repositorys offerings are yet at feature parity with our CentOS offering but given they are getting closer all the time I would like to inviting linux proficient / ideally developer capable forum members to try these rpms out. Another prerequisite is a familiarity with the state of our current Stable Channel updates function on CentOS. The main focus is on the Leap15.1 variant as that is what will become our Stable channel offering, which is a necessity for Rockstor’s sustainability. Tumbleweed is, for now, just a future indicator.
Please do not expect full function as this is simply not their, and familiarity with both of the above referenced docs is assumed as it is expected that you will be, as the testing channel is defined, contributing fixes while finding them. Or at least giving detailed and informed reports of your findings with hopefully some pointers as to the failure cause. Please do not report issues that you cannot re-produce.
Some but not all known issues are listed in the above wiki entry and in addition:
- The system drive is known to be non functional with regard to Rockstor created shares (they vanish after a few seconds). So any system used to test these rpms must have at least one dedicated data drive.
- The Web-UI ‘System Shell’ is non functional.
It is expected that as from 3.9.2-51 these rpms should be able to update themselves when new versions become available so the hope is that we can iterate, as before, within the testing channel, with the aim of initially reaching a CentOS feature parity, or near enough, where upon we can then establish our first openSUSE compatible Stable Channel release.
Initial requirements prior to rpm install.
- Apply all pending updates to the base openSUSE install.
- Establish and enable Network manager and stop and disable wicked
For the above 2 items see the linked wiki entry up until but not including “Packages for Building Rockstor from source”.
Import Rockstor’s public key, our rpms and repositories are now signed.
As the root user:rpm --import https://raw.githubusercontent.com/rockstor/rockstor-core/master/conf/ROCKSTOR-GPG-KEYAdd the relevant repository.
On a Leap15.1 install:zypper addrepo -f http://updates.rockstor.com:8999/rockstor-testing/leap/15.1/On a Tumbleweed install:
zypper addrepo -f http://updates.rockstor.com:8999/rockstor-testing/tumbleweed/and then:
zypper refreshBoth repos will be updated in sync and will carry the same version of Rockstor’s code, assuming both are able to build at the time of that release.
Again please note that these rpms are not nearly ready for production, but with skilled community feedback we can get them that way.
If you are particularly interested in this effort but are struggling with this install method, or need to ask more on how to do this, then please wait until our Alpha openSUSE based installer is released. It may not be all that long
Thanks to all those how have helped to get us this far. I’m chuffed to at least get here and special thanks to our forum moderator come major contributor @Flox who has done a tone of Rockstor on Leap15.1 / Tumbleweed testing / developing.
Again please only try these rpms if you are very familiar with linux and current Rockstor Stable Channel updates and have familiarised yourself with the above referenced docs. There is of course every intention of making these openSUSE compatible offerings our main stay, where upon they will be fit for purpose as best we can make them. But for the time being these are early developer releases that need a lot of work. But are nevertheless, within some areas, surprisingly functional.
Hope you enjoy the testing and remember that we are still supporting our current CentOS subscribers so please be patient.
Posts: 1
Participants: 1
@altatedi wrote:
I checked out the quick start guide and no option for Mac to create the Rockstor install USB?
Posts: 1
Participants: 1
@cmdywrtr27 wrote:
so i found out the hard way that the installation is supposed to be on a usb drive. first i installed it to the main hard drive in my computer that im using as a personal server and that went quick, no more than 15 minutes but i logged in and couldn’t create any pools because the entire hard disk was being used already for installation so i did some research and found out that im supposed to install Rockstor on to a usb drive and boot from there so im in the middle of installing it to a usb drive but so far im on day 2 and it still isn’t finished, its still going, it hasn’t stalled or anything but it is taking a really really long time. day one was just installation and that finished, now im on day two and i did ‘yum update’ and it has 714 updates it needs to do and its been about 2 hours and its only on number 12 so its going to take all night and probably all day tomorrow to update. so my question is, is this normal?! i have great internet connection and new hardware so i don’t know why it would be taking this long to install and update, has anyone else had this problem?
Posts: 1
Participants: 1
@phillxnet wrote:
Our services provider for this forum, our main web site, docs, Rock-ons, and all rockstor package updates has informed us that they are doing network maintenance/upgrades over the following period:
Start: 2020-01-07 21:00 UTC
End: 2020-01-08 01:00 UTCJust a head up and this may be no more than a few minutes outage during this period; hopefully.
Thanks all.
Posts: 1
Participants: 1
@shocker wrote:
Hello and happy new year!
I’ve been observed for the last week the system becomes unresponsive for some seconds but only when I’m copying something over NFS. There is no error in the btrfs dash but when I’ve checked the /var/log/messages I’ve seen that there are some pending sectors with a HDD.smartd[6711]: Device: /dev/sdk [SAT], 104 Currently unreadable (pending) sectors SMART Attributes Data Structure revision number: 16 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000b 100 100 016 Pre-fail Always - 0 2 Throughput_Performance 0x0005 134 134 054 Pre-fail Offline - 104 3 Spin_Up_Time 0x0007 170 170 024 Pre-fail Always - 371 (Average 403) 4 Start_Stop_Count 0x0012 100 100 000 Old_age Always - 31 5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 0 7 Seek_Error_Rate 0x000b 100 100 067 Pre-fail Always - 0 8 Seek_Time_Performance 0x0005 128 128 020 Pre-fail Offline - 18 9 Power_On_Hours 0x0012 096 096 000 Old_age Always - 30983 10 Spin_Retry_Count 0x0013 100 100 060 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 31 22 Helium_Level 0x0023 100 100 025 Pre-fail Always - 100 192 Power-Off_Retract_Count 0x0032 098 098 000 Old_age Always - 2641 193 Load_Cycle_Count 0x0012 098 098 000 Old_age Always - 2641 194 Temperature_Celsius 0x0002 222 222 000 Old_age Always - 27 (Min/Max 2/48) 196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0 197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 104 198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline - 0 199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 0 # btrfs device stats /dev/sdk [/dev/sdk].write_io_errs 0 [/dev/sdk].read_io_errs 0 [/dev/sdk].flush_io_errs 0 [/dev/sdk].corruption_errs 0 [/dev/sdk].generation_errs 0
Posts: 8
Participants: 2
@phillxnet wrote:
Just a friendly reminder that our last and now old CentOS based testing channel had a rather deceitful bug.
If you updated to Stable from 3.9.1-16 (last available CentOS based testing release), you have likely been affected by this issue. But if you subscribed to Stable directly from our last iso install, or a prior Stable channel install then you are likely not affected.
Essentially this bug would cause available version to be displayed as installed version within the Web-UI.
If you have subscribed to Stable and installed the apparent updates and don’t see an option to disable quotas on your pool then you are affected.
What you should see is a “Quotas” column in the Pools page table:
and it’s counterpart on each Pool Details page:
The one-off fix if you don’t see these quota options is to simply run, as root user:
yum updatein the terminal after subscribing to Stable channel updates.
But again if you see a quote disable option then you are NOT affected as this highly visible option was only introduced in the Stable channel after our last CentOS based Testing Channel release (3.9.1-16).
This highly irritating bug was fixed a long time ago but only after our now legacy CentOS based testing channel was no longer receiving updates.
Hope that helps.
And if you are no longer receiving Stable Channel updates as per:
then please check your subscription status and current Appliance ID in Appman (Appliance ID Manager):
A Sign Up / In is required with your ‘shop’ email address.
We do have a known update failure case for a limited subset of subscriptions which I will fix upon reporting to me your current Appliance ID via a private message here on the forum. Subscription extensions, and possible reactivation, will result if you are affected by way of an apology/compensation for not receiving rockstor package updates when they were due.
Posts: 2
Participants: 1
@jan5650 wrote:
Hi!
I have a very strange problem.
We use Rockstor with Active Directory.As you see in the picture we enabled AD, Rockstor Succesfully joined to the Domain and get the Domain users information too. We got a Share name: “WORK”. Every domain user got they own folder in the WORK share. Every user have full permission in own folder. It’s work great. BUT: if i copy a file into a user folder then the copied file’s owner will be the root (me) and the user cannot delete/write into it. If i enable Inheritate in the upper folder, then they got permission to write/delete a file, BUT tomorrow the permission perish. So tomorrow i need to change the permission again… Every day the permission gone…
What did we wrong, can you help us?
Thank!
Posts: 1
Participants: 1
@SatishI wrote:
I updated my system to 3.9.2-51 and after that I’m unable to start the samba service. Here is the error I get when I try to start the service. Any help would be appreciated.
Traceback (most recent call last): File "/opt/rockstor/src/rockstor/smart_manager/views/samba_service.py", line 113, in post systemctl('nmb', command) File "/opt/rockstor/src/rockstor/system/services.py", line 65, in systemctl return run_command([SYSTEMCTL_BIN, switch, service_name], log=True) File "/opt/rockstor/src/rockstor/system/osi.py", line 120, in run_command raise CommandException(cmd, out, err, rc) CommandException: Error running a command. cmd = /usr/bin/systemctl start nmb. rc = 1. stdout = ['']. stderr = ['Job for nmb.service failed because the control process exited with error code. See "systemctl status nmb.service" and "journalctl -xe" for details.', '']Here is the systemd logs
Jan 02 16:52:02 rockstor systemd[1]: Reloading. Jan 02 16:52:02 rockstor systemd[1]: Reloading. Jan 02 16:52:02 rockstor systemd[1]: Starting Samba NMB Daemon... -- Subject: Unit nmb.service has begun start-up -- Defined-By: systemd -- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel -- -- Unit nmb.service has begun starting up. Jan 02 16:52:02 rockstor nmbd[13048]: /usr/sbin/nmbd: error while loading shared libraries: libwbclient.so.0: cannot open shared object file: No such file or directory Jan 02 16:52:02 rockstor systemd[1]: nmb.service: main process exited, code=exited, status=127/n/a Jan 02 16:52:02 rockstor systemd[1]: Failed to start Samba NMB Daemon. -- Subject: Unit nmb.service has failed -- Defined-By: systemd -- Support: http://lists.freedesktop.org/mailman/listinfo/systemd-devel -- -- Unit nmb.service has failed. -- -- The result is failed. Jan 02 16:52:02 rockstor systemd[1]: Unit nmb.service entered failed state. Jan 02 16:52:02 rockstor systemd[1]: nmb.service failed. Jan 02 16:52:03 rockstor dockerd[5839]: [20200102 16:52:03.152] TRACKER[66.165.233.194:4000, [2604:4500:9:58::10]:4000] requesting peers for [1299] Jan 02 16:52:03 rockstor dockerd[5839]: [312B blob data] Jan 02 16:52:03 rockstor dockerd[5839]: [20200102 16:52:03.181] TRACKER[66.165.233.194:4000, [2604:4500:9:58::10]:4000] got message from 66.165.233.194:4000/uTP[0x00007fb73c027850]: { "m": "peers", "peers": [ Jan 02 16:52:03 rockstor dockerd[5839]: [20200102 16:52:03.181] Tracker [66.165.233.194:4000, [2604:4500:9:58::10]:4000] time is 1578012723 Jan 02 16:52:03 rockstor dockerd[5839]: [20200102 16:52:03.181] SD[1299]: Got list of 0 peers Jan 02 16:52:07 rockstor dockerd[5839]: [20200102 16:52:07.239] 16TunnelConnection[0x00007fb73d9baf60]: received ping
Posts: 3
Participants: 2
@JediAaron wrote:
(topic withdrawn by author, will be automatically deleted in 24 hours unless flagged)
Posts: 1
Participants: 1
@Rushby_Craig wrote:
[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
Configuring SAMBA in Rockstor and assigned two shares with two admin users
Detailed step by step instructions to reproduce the problem
[write here]
Web-UI screenshot
Error Traceback provided on the Web-UI
Traceback (most recent call last): File "/opt/rockstor/src/rockstor/smart_manager/views/samba_service.py", line 114, in post systemctl('smb', command) File "/opt/rockstor/src/rockstor/system/services.py", line 64, in systemctl return run_command([SYSTEMCTL_BIN, switch, service_name]) File "/opt/rockstor/src/rockstor/system/osi.py", line 115, in run_command raise CommandException(cmd, out, err, rc) CommandException: Error running a command. cmd = /usr/bin/systemctl start smb. rc = 1. stdout = ['']. stderr = ['Job for smb.service failed because the control process exited with error code. See "systemctl status smb.service" and "journalctl -xe" for details.', '']
Posts: 2
Participants: 2
@anborn wrote:
Brief description of the problem
Rockstor unable to start due to wrong rights on root filesystem
Detailed step by step instructions to reproduce the problem
unfortunately I changed owner in root filesystem and all subfolders to root. Now rockstore is unable to start anymore. No BTRFS mounts of my pools and shares
What do I have to change to fix it or is it possible to install the server again to get access to my data on the disks=Web-UI screenshot
not available
Error Traceback provided on the Web-UI
not available
Posts: 2
Participants: 2
@ayumifanshawn wrote:
hello so far love this software after trying many others if i can get this on issue resolved it will be perfect!
my setup vmware esxi 6 running on a dell r720 my disks are connected to a netapp disk shelf the drives are sata this is connected to a lsi controller that is just passing the disks to rockstor version 3.9.1-0.
my issue is i know these drives support standby as they worked in freenas but the hourglass icon is grayed out and i am unable to enter the apm settings.
i found this post
it is 4 years old and tried a few of the suggestions but they did not work or i did not fully understand them or may be the fact that this is 4 years old im not very familiar with linux at all so if any one has a sugestion or where to start pleas explain it for a linux noob thanks in advance!
Posts: 4
Participants: 2
@ayumifanshawn wrote:
just curious as i see this raid 5/6 was implemented in 2016 and was not recommend for use but now in 2020 how is it this is the only software that does everything i want but only this is a huge caveat if i can not rely on raid 5/6 then im back to the drawing board has any one used it with/without issue?
Posts: 1
Participants: 1
@jakeyg wrote:
I started having troubles when i uploaded some files to my rockstor and the upload started to go super slow, then drop out, then reconnect etc. So i logged into the rockstor box and there was an error in red
" Pool Device Errors Alert"
I went back into FTP nad i couldnt delete
Error: rmdir /mnt2/*******: received failure with description ‘Failure’there are about 100GB free of a 5TB pool.
Can anyone shed some light on whats going on>? Could my drives be failing? I cant see any info around this in the drives page.
Posts: 1
Participants: 1
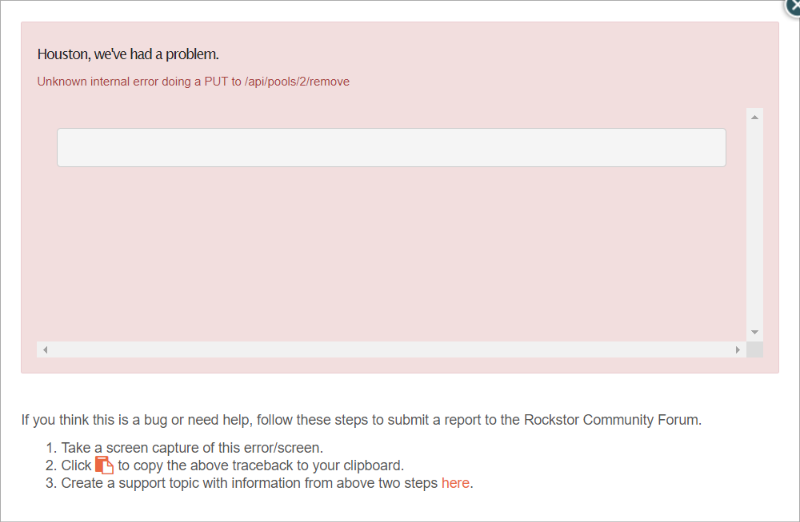
@legion wrote:
[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
Attempting to remove snapshots fails.
Detailed step by step instructions to reproduce the problem
Selecting snapshots in list, and selecting the Delete button.
Web-UI screenshot
Error Traceback provided on the Web-UI
N/A. There is just an empty field as seen in the screenshot.Thanks in advance for any assistance.
Posts: 2
Participants: 2
@Natep wrote:
[Please complete the below template with details of the problem reported on your Web-UI. Be as detailed as possible. Community members, including developers, shall try and help. Thanks for your time in reporting this issue! We recommend purchasing commercial support for expedited support directly from the developers.]
Brief description of the problem
[Unknown internal error doing a POST to /api/commands/update-check
]Detailed step by step instructions to reproduce the problem
[I just clicked on the update now button when I finally got the OS installed and gained access to the web ui. After about 5 minutes of a spinning wheel it gave me the "Unknown internal error doing a POST to /api/commands/update-check
" message!Web-UI screenshot
Error Traceback provided on the Web-UI
[Unknown internal error doing a POST to /api/commands/update-check ] That's all there was.
Posts: 1
Participants: 1